In this project we will implement machine learning algorithms to predict the directional returns of ETF's. Our goal will be simple, predict over a given horizon whether a given ETF will go up or down. We will thus employ several classification algorithms and multiple strategies to predict ETF returns.
We get the data of the following 10 ETF's which represent broad sectors of the market
- SPY—SPDR S&P 500; U.S. equities large cap
- IWM—iShares Russell 2000; U.S. equities small cap
- EEM—iShares MSCI Emerging Markets; Global emerging markets equities
- TLT—iShares 20+ Years; U.S. Treasury bonds
- LQD—iShares iBoxx $ Invst Grade Crp Bond; U.S. liquid investment-grade corporate bonds
- TIP—iShares TIPS Bond; U.S. Treasury inflation-protected securities
- IYR—iShares U.S. Real Estate Real estate
- GLD— SPDR Gold Shares; Gold
- OIH—VanEck Vectors Oil Services ETF; Oil
- FXE—CurrencyShares Euro ETF; Euro
For explanation purposes we will usually be using SPY.
Individual ETF Analysis
We will begin by trying to predict the daily directional change of individual ETF's. Our original data frame gives the following information .
 |
| Original ETF DataFrame |
Feature creation
Below we have also plotted the adjusted closing price for the SPY ETF over the 5 year period
 |
| SPY plotted over the 5 years period |
When we have the raw adjusted closing prices then we need to create additional features to quantify the momentum and the history of an ETF. We engineered the following features
- Dummy variables for month and day of the week
- Previous 1, 2, 3, 4, 5 and 7 day percent changes of the price
- Cumulative sum of the 1 day percent changes
- 7, 50 and 200 day exponentially weighted moving average (EWMA)
- Relative Strength Index (RSI) and Moving Average Convergence Divergence (MACD)
- Day's variances (High-Low), (Open- Close), (Open - Previous Close), (High - Close)
- Previous Hot (Cold) Streak (previous no. of consecutive days when the ETF went up (down))
- Current Hot (Cold) Streak (no. of consecutive days when the ETF went up (down) in the ongoing streak)
- Permutations of differences in Previous and Current, Hot and Cold streaks
Then including the original feature of volume leaves us with 41 features with which we perform our classification analysis. The continuous features are normalized before analysis. The classification target is the directional change of the ETF adjusted closing price (up or down) for the next trading day and is binary. Plotted below are the correlations of the target variable with both continuous and discrete variables. We have also plotted a correlation matrix with the continuous variables. As can be seen the correlation is fairly weak.
 |
| Correlations of 0 or 1 return with continuous and discrete variables |
Algorithms used
We will use Random Forest, Gradient Boost (XGBoost), Support Vector Machine (SVM) and Logistic Regression as our classification algorithms. We will also tune the hyperparameters of each algorithm using GridSearchCV. For cross-validation, we use k-fold cross validation (instead of time series cross-validation). Let us explain in what follows the choice of hyperparameters we make for each algorithm.
Random Forest
Number of trees - 100 (Given that all other hyperparameters are same, increasing number of trees just reduces the statistical variance in prediction, and choosing large enough number of trees is sufficient. See
here for an explanation)
Criterion - [gini, entropy] (Criterion for selecting feature at each node)
Max Depth - [None, 2, 3, 5, 10] Depth of the trees built
min_samples_split - [5,10,15] minimum samples at a node to split it
min_samples_leaf - [3,5,9,13] minimum samples required in a leaf
XGBoost
max_depth: range (2, 10, 2),
n_estimators: range(20, 120, 20),
learning_rate: [0.001,0.003,0.01, 0.03, 0.1]
Logistic Regression
fit_intercept: [True,False],
solver:['liblinear'],
C: np.logspace(0,4,5),
penalty: ['l2']
Support Vector Machine
coef0 = np.array([0.25,0.5, 1,2,4])
gamma = np.array([0.0001,0.001, 0.01,0.1])
degree = np.array([2,3, 4])
Establishing a baseline
As good scientists we must always establish a baseline to evaluate how well our model performs compared to the baseline. For our baseline we will introduce a criterion which we call "Information Gain", borrowed from (
Liew). although we have modified the definition. "Information Gain" (IG) is defined as the difference between the accuracy predicted by our models and expected accuracy by randomly generating the probablility distribution suggested by the training set. Since we use this criterion throughout the analysis we will describe our choice here in some detail.
IG = ModelAccuracy - F(x,y)
where F(x,y) = x*y -(1-x)*(1-y) is the expected accuracy where x is the number of positives in the test set and y is the number of positives in the training set. Note that this definition comes from the assumption that our algorithms at minimum has learned the probability distribution of our training set, (i.e. it knows the fraction of positives and negatives) and tries to randomly predict that on our test set. Any improvement beyond that would signal a model that is correspondingly better trained. This metric of "Information Gain" is a little convoluted compared to that of just Model Accuracy, or Model Accuracy - Naive Accuracy, where Naive accuracy is accuracy with precision of 1 i.e. predict all positives. We can show (see Jupyter Notebook), our definition of information gain centers the distribution of information gain around 0, aligns distributions across ETF's and lowers the standard deviation. It also don't get penalized for having a much higher or lower positive rate. This improvement will be more evident when we discuss higher differences in positive rates for larger horizons.
On each data set (ETF's or random data) we then perform a train-test split multiple times to generate a distribution of Information Gain. Comparing the Information Gain between our ETFs and randomly generated ETFs we can distinguish our strategies. Now we will show the information gain with each algorithm for all the random data sets.
Random data baseline
For the baseline we generated five random ETF charts. We start with the same timestamps as our other ETF's. We set the first day closing price to 1. Then for the next day closing price we multiply the previous day closing price by (1+ rand), where rand is a randomly generated number from gaussian distribution with standard deviation equal to the standard deviation of the daily returns from SPY (the true distribution of returns is not gaussian but we can assume that to create random prices.) . We then also create the daily High, Low, and Open prices by assuming that they have a random gaussian distribution in relation to closing prices (once again we use SPY data to quantify this). We make five such EFT charts shown below, with a fair cross-section of ETF's that increase and decrease in. value over the 5 year period.
 |
| Randomly Generated ETF's |
We then try to predict the accuracy of the random ETF dataframes using our algorithms described above. This gives us a baseline of how high we can expect the accuracy to be compared to our naive prediction of buying and holding. We generate random splits in our training and testing data sets and perform a fit each split to generate a distribution of "Information Gain" defined above for each of our algorithms and each of the random data sets. Below we have plotted the Information Gain for each algorithm and each randomly generated data set. The KDE plotted below is generated from a distribution of 60 data points for every ETF.
 |
| Information Gain for the randomly generated ETF's |
ETF Analysis
Below we plot the 10 ETF's normalized to 1 at the beginning for visualization purposes
 |
| 10 ETF's we consider for our analysis |
Below we plot the information gain KDE for each ETF and for each algorithm below. The KDE is generated using 60 datapoints (random train-test splits) for each ETF
 |
| Information Gain for the ETF's |
Now we need to understand whether our analysis on an ETF actually gains us more information than a random data analysis. Since we cannot assume that the information gain distributions are normally distributed, we cannot perform the standard Welch's t-test. Instead we will perform a Monte Carlo test. For a Monte Carlo test (as we have described in
other blogpost), we take the distributions we are to compare, merge them, then split the merged distributions randomly into sizes of the original dataframe. We subtract the means of the randomly generated splits. Repeating this process a lot of times generates a distribution of mean differences that is normally distributed. We then count the percentage of mean differences that were greater than the mean difference of our original data sets which is our p value. The power of the Monte Carlo approach is that it is a non-parametric test and no assumptions are made about the underlying distribution.
Below we make a table of the max p-value among the 5 random distributions for every ETF and every method
 |
| p-values of ETF information gains when compared to all the random ETF's |
As we can see some p-values are below our threshold 0.05, but most methods fail to distinguish between a random dataframe and an ETF. We ignore the inf entries, they are merely indicating that the mean of the real ETF is lower than at least one randomly generated ETF. Let us now plot some the ETF's for which we actually might have a signal, i.e. even the closest random information gain distribution is not close enough to give a higher p-value
 |
| Information Gain of ETF's which give statistically higher IG compared to their closes random counterpart |
We see a potential signal in GLD, OIH, IWM, IYR and LQD. Further discussion is in Conclusions.
Combined ETF Analysis
So far we have only analyzed individual ETF's separately. We have chosen 10 ETF's that represent a broad cross-section of the market. Assuming the ETF is a closed system (obviously it's not) one can imagine that the gain of one ETF is loss of another. Any correlations within ETF's should be exploited. Thus in this section we will do an analysis where we perform the analysis on all the ETF's combined. We will try to reproduce this paper by
Liew and Mayster .
Liew Mayster Analysis
In the work cited above, the authors consider the change in the ETF price over a horizon "n". n takes the values [1,2,3,5,10,20,40,60,120,250] days. Then the following features are generated with P as the price of the ETF on a given day and V it's volume
- t lagged n day returns, XA = {r(t-n,t), r(t-n-1,t-1),..., r(t-n-j,t-j)}, where r(t-n, t). = P(t-n)/P(t) -1
- t lagged n day average volumes XB = {V(t-n+1,t), r(t-n,t),..., r(t-n-j+1,t-j+1)}
- Dummy variables for month and week.
Combining all these features for all the 10 ETF's we can generate a dataframe to use our algorithms on. One of the ETF's is then chosen as a target ETF. In the paper, they describe a criterion for information gain which is a little different than the definition we used above. To calculate information gain, they replace the dataframe created above with a random dataframe from a univariate distribution between 0 and 1 for all the continuous features. Then the difference in accuracy between the ETF dataframe and the random data frame is called "Information Gain". We will use our original definition of information gain, and we will compare the distribution of information gain from the ETF's vs the random data to see if we find a signal over differing time horizons.
Liew and Mayster then report seeing a significant information gain of one increases the horizon. We have plotted a figure from their paper below for comparison
 |
| Image from Liew and Mayster showing information gain for SPY using various algorithms
|
Our analysis
First we will begin by explaining the difference between our analysis and the analysis in
Liew and Mayster. We define "Information Gain" as above. We then compare the distribution of "Information Gain" of the ETF's to the distribution we gain from the random ETF's we generate to see if we get a signal. Our random ETF's are more realistic compared to the ones in
Liew and Mayster because instead of imputing radom values between 0 and 1 in our dataframes, we construct a new ETF as a "random walk" as described before. We also use RF, SVM, XGB and Logistic Regression for our classification algorithms whereas
Liew and Mayster use Deep Neural Nets, RF and SVM. We present our results below. We only go up till n = 10 in our Horizon in the interest of computational time and we analyze n = 1,5 and 10
Horizon 1
 |
| p-values of ETF information gains when compared to all the random ETF's with horizon=1 |
We ignore the inf entries, they are merely indicating that the mean of the real ETF is lower than at least one randomly generated ETF. All ETFs except GLD and OIH show p- values < 0.05. Curiously those are the pnes that have a negative growth over 5 years. Below we plot information gain of SPY for RF and XGB algorithms compared to the random ETF gains.
 |
| Information Gain of SPY compared to randomly generated ETF's with horizon=1 |
Horizon 5
Below we show the table of p-values distinguishing the real etf "Information Gain" over random etf gains.
 |
| p-values of ETF information gains when compared to all the random ETF's with horizon = 5 |
Entries with inf are not applicable since the mean of the ETF is lower than all the random ETF in that case. There are multiple entries with p < 0.05 for all ETF's. RF and XGB seem to give a signal for all ETF's while Log and SVM don't work for most ETF's. As an example we will plot SPY against random RF and XGB below.
 |
Information Gain of SPY compared to randomly generated ETF's with horizon=5
|
Horizon 10
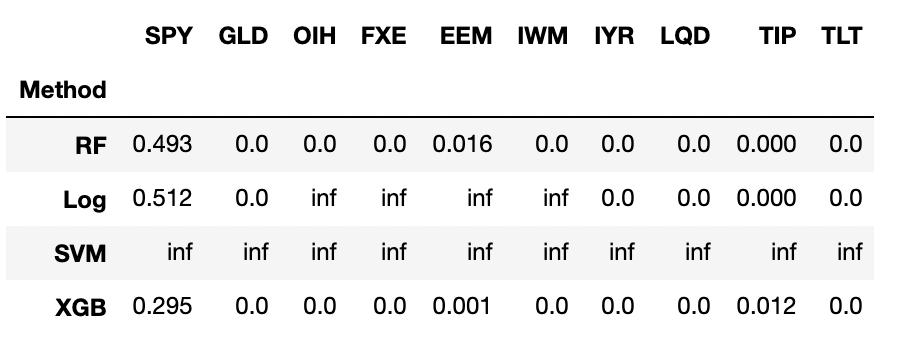
Below we show the table of p-values distinguishing the real etf "Information Gain" over random etf gains.
 |
| p-values of ETF information gains when compared to all the random ETF's with horizon=10 |
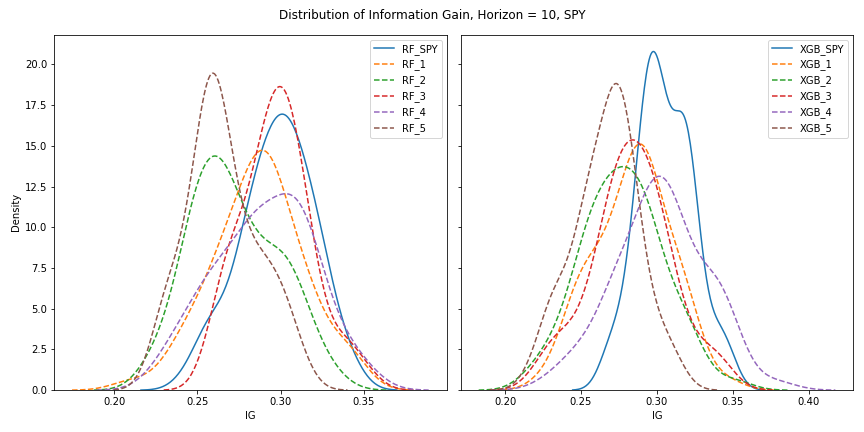
Entries with inf are not applicable since the mean of the ETF is lower than all the random ETF in that case. Every ETF except SPY shows a signal. We will plot SPY against random RF and XGB below.
 |
Information Gain of SPY compared to randomly generated ETF's with horizon=10
|
Conclusion and Future Work
Daily Analysis
We find a signal in SPY, OIH, IWM, IYR, LQD. In most of the cases RF or XGB algorithm gives a positive signal.
However before making such a bold claim it's important to remember that our analysis only suggests that we might be able to get better accuracy compared to a random ETF, however our returns could be worse compared to zero. Also we only consider 5 different random ETF's. It's possible that considering more, we would get a p-value above our threshold of 0.05. A more detailed statistical analysis is needed to address this question. It is of interest why this method works on certain ETF's and not others and should be investigated further.
Finally we need to implement this strategy in live markets to see it's potential. We will implement this in the future. For future work we will consider following improvements.
- Increase horizon size and combine ETF's together, keeping the features the same.
- Macroeconomic data such as employment numbers, retail sales, industrial production, consumer confidence etc.
- Use NLP to scan financial news headlines and generate features (This is harder than it sounds because each ETF represents a collection of different companies which different news sources can affect)
- Try different algorithms (Neural Nets, Stacking etc.)
- If a significant signal is found, try running the algorithm on active markets
Combined ETF Analysis
When we combine the ETF's we see a signal even for horizon of one day for most of our ETF's. For SPY however as we increased the horizon size for our predictions, the predictions got worse with no prediction compared to the random ETF's for horizon size of 10. This is contrary to what's shown in
Liew and Mayster. It is not clear why we reach different conclusions. A difference could be because they compare their information gain to a randomly generated ETF distribution constructed from univariate numbers between 0 and 1, but we compare it to a random walk which should be a better comparison in theory. The difference in our conclusions should be investigated further.
Increasing horizon size could give a larger gain for most ETF's however it's important to remember once again that our analysis only suggests that we might be able to get better accuracy compared to a random ETF, however our returns could be worse compared to zero. Increasing horizon size could also mean lower overall returns, even for higher accuracy since profits compound. The ideal horizon should be investigated. We should also see if this stands the test of live markets.
In conclusion though the overall results may need more exploration and testing in live markets, we now have a solid framework to understand which algorithms have potential to work and to quantify how well it works.

















Comments
Post a Comment